Dev Journal 01 - Building a Jiu Jitsu Film Retriever
I need to be able to retrieve jiu jitsu film for 3 general battles that happen in the sport. I am sorry if I offend any jiu jitsu practicioners with these definitions. Email me if you disagree. Or text me if you have my number :).
- Standing Battle
- When both opponents are on a foot or knee, moving to take the other opponent to the ground.

- Guarded Battle
- When one opponent is seated or supine with their legs in front of the other opponent.

- Pinning Battle
- When one opponent is past the other opponent’s legs.

Progress so far
- I started with gathering various matches I could find on youtube and splitting the videos up into frames of each second of the match. I ended up with 12,000 frames. I proceeded to annotate each frame with 1 of the 4 classes: standing, pinning, guarded, none. I got to 4,000 annotated frames before deciding to test it on my custom CNN. Data Collection and Annotation Jupyter Notebook
- I got 53% on my testing dataset which is better than random guessing so the classifier is learning something. The confusion matrix at the end of this notebook showed that a lot of guarded predictions are actually pinning which makes sense since those two positions are closely linked. The only difference is if the seated or supine opponent’s legs are in front of the other opponent. CNN Training/Evaluating Jupyter Notebook
- From there I decided that we need to use a pose estimation tool to help the network find and link the relativities of the limbs of both players to the 3 situational battles. For this I decided to use Alpha Pose and it had trouble putting bounding boxes on two jiu jitsu players that were attached to each other. The neural network did not understand that it was seeing two different people and just assumed it was one person. I also had a difficult time setting up Alpha Pose and had to clone it and make changes to it and use my own version to actually get it working. This was before I realized that the newer Yolo models Yolov7-v11 has pose estimation built in to it. And its newer and better than AlphaPose. Alpha Pose Jupyter Notebook

- AlphaPose Estimation
- I also tried the most advanced YoloV11 model and ended up with similar results. The network could not distinguish that it is seeing two different people. Yolo V11 Jupyter Notebook
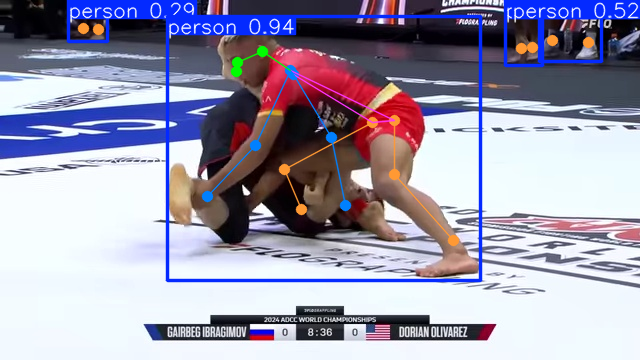
- YoloV11 Pose Estimation
- I think AlphaPose is actually better than YoloV11 since YoloV11 is more of a general purpose object detecter while AlphaPose is specifically designed for pose detection. YoloV11 is a single step architecture for pose detection though it is not using multiple networks(steps) to do pose estimation like AlphaPose. AlphaPose uses Yolov3 for detecting bounding boxes then its using a resnet for pose estimation.
- The benchmarks show the Intersection over Union which is the area of the predicted box overlapped with the area of the ground truth box. Then we calculate the precision and take the average precision (AP) or Mean Average Precision (mAP) over the test set.
- For the COCO dataset evaluation mAP and AP mean the same thing. In some contexts, AP is calculated for each class and averaged to get the mAP. But in others, they mean the same thing. For example, for COCO challenge evaluation, there is no difference between AP and mAP.
- “AP is averaged over all categories. Traditionally, this is called “mean average precision” (mAP). We make no distinction between AP and mAP (and likewise AR and mAR) and assume the difference is clear from context. COCO Evaluation” Reference Article
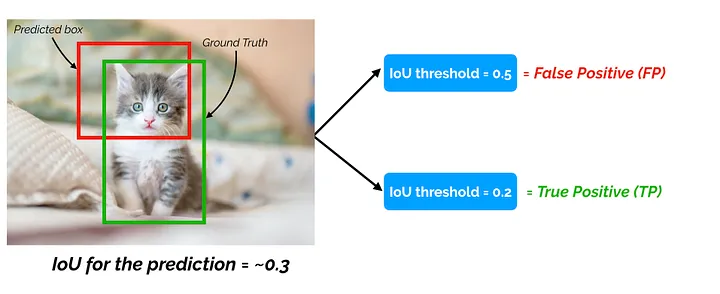
- Intersection over Union example
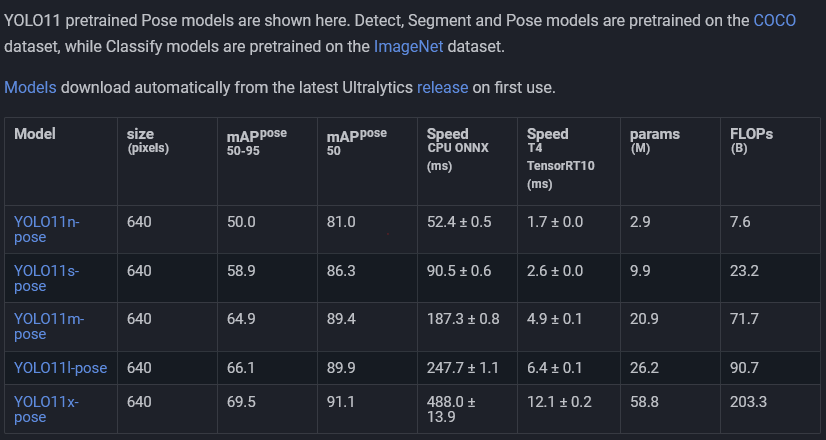
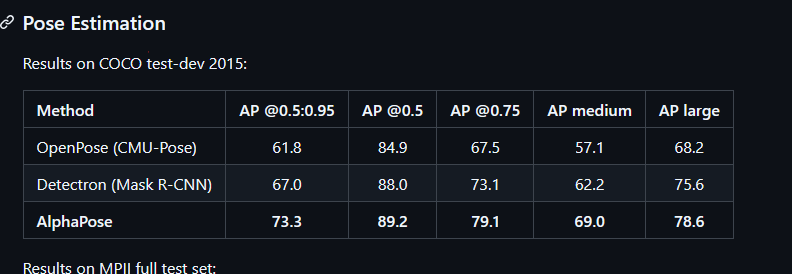
- This shows Alpha Pose might be better than YoloV11 if you pay attention to AP 0.5 and AP 0.5-0.95. But who really knows and its a small enough difference that I can use whichever one is easier to use which at this point is YoloV11.
- TODO:
- I think I want to train a model to specifically detect poses on jiu jitsu players. It seems like models do not have this in their training sets and they should because there are a lot of interesting cases of occlusion there. I have the intuition that I can train a neural network to do pose estimation for jiu jitsu specific occlusion cases because of outputs like these for AlphaPose and YoloV11:

- AlphaPose Object Detection with Occlusion

- YOLOv11 Object Detection with Occlusion
- See if it can handle these complicated situations of occlusion above then it can handle my jiu jitsu scenarios.
- I should try to get bounding boxes to show up for both jiu jitsu players who are deeply entangled.